A gentle reminder about metadata
It’s important that ‘information workers’ understand what metadata (often called ‘tags’) is and the need for capturing appropriate metadata for your documents and information items. Not adding metadata is initially quicker, but everything you do with the document later is slower and the chance of making a mistake is greater.
metadata
[ˈmɛtədeɪtə]
NOUN
a set of data that describes and gives information about other data.
Metadata is simply data about things, commonly documents and core data; it describes what something is and helps identifying it and allow it to be processed in useful ways.
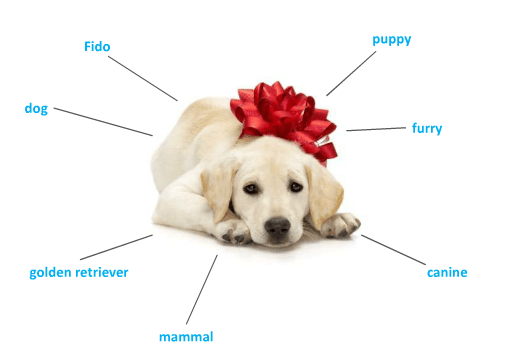
Let’s consider a simple example. Take an example of a golden retriever puppy; the puppy is the item or object, the fact that it is a golden retriever and a puppy describes the object. In fact, there is much more metadata we could apply:
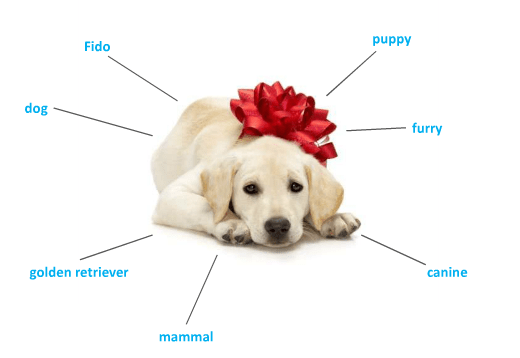
Depending on what you need to do, you would use a selection of metadata that allows you to manage what you know about this object.
Firstly, it’s really useful for searching. Consider a search for “dog” and “golden retriever puppy”. The search results would be very different:

Clearly the specific search is more quickly finds exactly what you are after, but only if someone has added the metadata to the information.
You may need to know more about this particular dog; things that aren’t obvious from the picture; how about its personality. It looks friendly enough, but what if the metadata for Personality says, “Extremely lively” or even “Vicious”. What about it’s health? Maybe metadata on it’s injections and vaccinations are useful things to know. It would be good to be able to see this about a variety of dogs, or even filter out those with undesirable characteristics for your particular purpose.
Stop with the dogs, what about documents?
Following is a simple set of metadata you can capture/tag a document or content with:
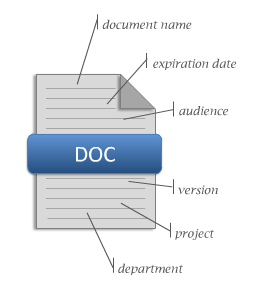
The metadata can then be used to group content together, for example you have a document which is to do with appraisal of a GP practice within a borough. Here you have three sets of metadata you can define:
1. The category of the document, in this case Appraisal
2. Borough
3. Practice
If you attach the above metadata to the document, you can then group all documents that are appraisal documents, or all documents relating to a particular borough or a GP practice. Furthermore, you can group them by multiple categories, that way you can see all the documents for a borough grouped by GP practice and by category of the documents, not just as a long list of file names.
Without metadata, it will just be a bucket where files are uploaded to and never found.
With metadata, you can create different views of your documents and information to serve different needs; you can find the things you need quickly using search, and you can see critical information (such as whether the document has expired, or been sent to a client), without having to open it or check another system.
Here is an example, showing a large list, grouped by category. With a single click other views can be selected, such as by technology or filtered to only certain items (Office 365, for example):

So… metadata…. it’s really useful then
It isn’t that hard to apply (Microsoft Word has a panel that lets you add it directly while typing up the document). It ensures large lists or stuff (documents, information, pictures, etc.) does get horribly messy, so that you can find things. It allows you to do things like archive all the old items, or assign them to someone else to update. It stops you having to use folders (which are an absolutely terrible way of storing most things). It makes like better for you, you colleagues and your company.

2 replies on “Do I really have to add metadata?”
It’s interesting that MS seem keen on hiding out in places like OneDrive. Also the OneDrive client isn’t conducive to providing it if you tend to use that for synced SharePoint libraries instead of a browser
Yep – OD is definitely to low end cloud storage for beginners! I find it frustrating that there is no option to expose teh metadata capabilities that are hidden in OD4B, but I can live with that as long as they get their act together on the SharePoint platform.
There is also the whole legacy of SharePoint and OneDrive being 2 different teams, with different attitudes towards what users need. I kind of agree that all some people need is a dumb directory structure in the cloud, but that misses the point that other people need more. The improved ability to move content between OD4B and SPO should encourage some level of metadata capture in OD4B, but the team hasn’t really worked on that.
There are some UserVoice comments on the matter – always worth adding more
https://office365.uservoice.com